Nautilus, le nouveau moteur de recherche de Dropbox

Ces derniers mois ont été plutôt chargés pour l’équipe Dropbox responsable de l’infrastructure de recherche : elle a mis au point un nouveau moteur de recherche en texte intégral nommé Nautilus, destiné à remplacer notre ancien moteur de recherche.
Pour Dropbox, la recherche constitue un défi de taille. Nous gérons des centaines de milliards de contenus, mais tenons à offrir une expérience de recherche personnalisée à chacun de nos 500 millions d’utilisateurs inscrits. Cette personnalisation prend différentes formes : chaque utilisateur a accès à des documents différents, mais il a aussi des préférences et des comportements de recherche spécifiques. La personnalisation des moteurs de recherche Web, quant à elle, se concentre presque exclusivement sur ce second aspect, avec toutefois un corpus de documents en grande partie identique pour chaque utilisateur (si l’on met de côté les différences géographiques).
En outre, une partie du contenu que nous indexons pour la recherche évolue fréquemment. Imaginons, par exemple, qu’un ou plusieurs utilisateurs travaillent sur une présentation. Ils vont enregistrer plusieurs versions du document au fil du temps, et pour chacune d’entre elles, les termes de recherche qui permettront de retrouver le document changeront peut-être.
Plus généralement, nous souhaitons aider les utilisateurs à retrouver les documents les plus pertinents, pour une recherche donnée et à un moment donné, de la manière la plus efficace possible. Pour cela, il faut pouvoir utiliser l’intelligence artificielle à différentes étapes du processus de recherche, qu’il s’agisse de machine learning au niveau du contenu (comme les systèmes capables d’analyser les images) ou de systèmes d’apprentissage capables de mieux classer les résultats de recherche en fonction des préférences de chaque utilisateur.
De plus, ce type de système exige un grand nombre d’itérations pour atteindre le résultat escompté. Il est donc primordial de pouvoir faire des tests avec différents algorithmes et sous-systèmes afin de l’améliorer progressivement, composant par composant. Voici les principaux objectifs que nous nous étions fixés au lancement du projet Nautilus :
- Offrir des performances, une évolutivité et une fiabilité adaptées à la taille de notre infrastructure de données
- Fournir une base pour l’implémentation de fonctionnalités intelligentes de classement et de récupération de documents
- Concevoir un système flexible permettant à nos ingénieurs de personnaliser facilement l’indexation des documents et les canaux de traitement des requêtes de recherche pour faire des tests
- Atteindre ces objectifs rapidement, de manière fiable et avec des mécanismes de protection renforcés pour préserver la confidentialité des données de nos utilisateurs, comme avec tous nos systèmes gérant le contenu de nos utilisateurs
Dans cet article de blog, nous présentons l’architecture du système Nautilus et ses principales caractéristiques, nous décrivons les choix que nous avons faits en matière de technologies et de conception, et nous expliquons comment nous exploitons le machine learning à différents niveaux du système.
Architecture globale
Nautilus se compose de deux sous-systèmes pratiquement indépendants : l’indexation et le service.
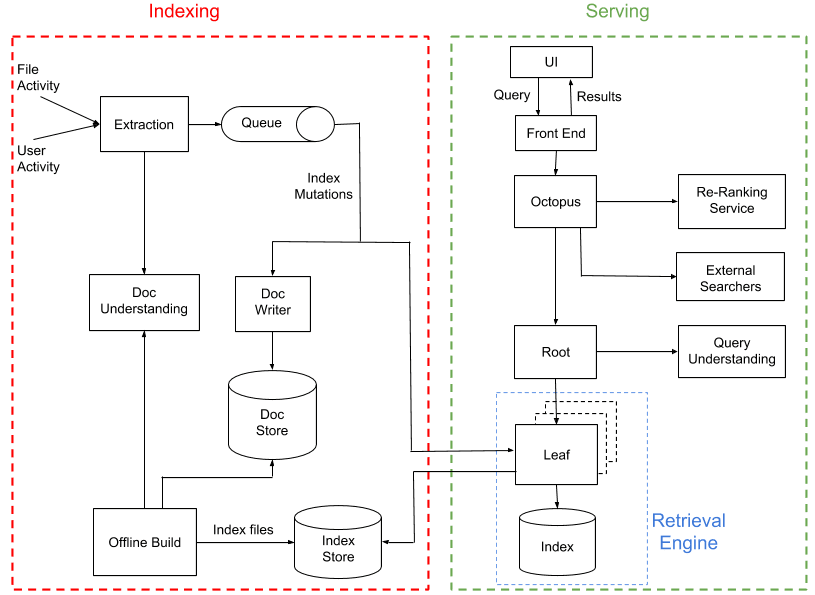
Le processus d’indexation a pour objectif de traiter l’activité liée aux fichiers et aux utilisateurs, d’extraire le contenu et ses métadonnées, et de créer un index de recherche. Le système de service utilise ensuite cet index de recherche pour renvoyer un ensemble de résultats en réponse aux requêtes des utilisateurs. Ensemble, ces systèmes couvrent plusieurs datacenters Dropbox dispersés géographiquement, exécutant des dizaines de milliers de processus sur plus de 1 000 hôtes physiques.
La manière la plus simple de créer un index serait de parcourir régulièrement tous les fichiers stockés dans Dropbox, de les ajouter à l’index et de permettre au système de service de répondre aux requêtes. Toutefois, un tel système ne serait pas capable de suivre les modifications apportées aux documents en temps réel. Nous avons donc suivi une approche hybride, relativement courante dans les systèmes de recherche à grande échelle :
- Nous générons régulièrement des versions « hors ligne » de l’index de recherche (tous les trois jours en moyenne).
- À mesure que les utilisateurs interagissent avec les fichiers et entre eux, par exemple en cas de modification ou de partage de fichiers avec d’autres utilisateurs, nous générons des « mutations d’index » qui sont ensuite appliquées à l’index en ligne et à une banque de documents persistante, quasiment en temps réel (avec un délai de quelques secondes).
Nous aborderons également d’autres aspects importants du système, comme la manière dont nous indexons les différents types de contenu, en utilisant notamment le machine learning pour « comprendre les documents », et la façon dont nous classons les résultats de recherche générés (y compris à partir d’autres index de recherche) à l’aide d’un service de classement basé sur le machine learning.
Partitionnement des données
Avant d’aborder les sous-systèmes spécifiques de Nautilus, expliquons brièvement comment notre moteur de recherche peut fonctionner à une telle échelle. Les centaines de milliards de contenus que nous gérons représentent une quantité pharaonique de données à indexer. C’est pourquoi nous divisons, ou « partitionnons », ces données sur plusieurs machines. Nous devons donc décider comment partitionner ces fichiers de telle sorte que les requêtes de recherche de chaque utilisateur renvoient des résultats rapidement, tout en équilibrant la charge autant que possible sur toutes nos machines.
Chez Dropbox, nous utilisons déjà un schéma similaire pour regrouper les fichiers dans des « espaces de noms ». Ces espaces de noms sont comparables à des dossiers auxquels un ou plusieurs utilisateurs ont accès. L’un des avantages de cette approche, c’est qu’elle nous permet de n’afficher que des résultats de recherche uniquement parmi des fichiers auxquels ils ont accès (c’est d’ailleurs sur ce principe que se basent les dossiers partagés). Par exemple, le dossier devient un nouvel espace de noms auquel le créateur et le destinataire ont accès. L’ensemble de fichiers auquel un utilisateur Dropbox a accès est entièrement défini par l’ensemble d’espaces de noms sous-jacents auquel on lui a donné accès. Au vu des propriétés citées plus haut des espaces de noms, lorsqu’un utilisateur recherche un terme, nous devons effectuer une recherche dans tous les espaces de noms auxquels il a accès et combiner tous les résultats. Cela signifie également qu’en transmettant les espaces de noms au système de recherche, nous recherchons uniquement le contenu auquel le créateur de la requête a accès au moment où la recherche est exécutée.
Nous regroupons les espaces de noms dans des « partitions », qui sont des unités logiques sur lesquelles nous stockons, indexons et servons les données. Nous utilisons un schéma de partitionnement qui nous permet de facilement repartitionner les espaces de noms en fonction des besoins. Nous utilisons actuellement 2 048 partitions.
Indexation
Extraction et compréhension du contenu des documents
Sur quels éléments les utilisateurs font-ils une recherche ? Évidemment, il y a le contenu de chaque document, en d’autres termes, le texte du fichier. Mais il existe également de nombreux autres types de données et de métadonnées pertinentes pour les recherches.
Nous avons conçu Nautilus pour qu’il gère tous ces éléments, et plus encore, de façon flexible grâce à la possibilité de définir un ensemble d' »extracteurs ». Chacun d’entre eux extrait un résultat à partir du fichier d’entrée et l’écrit dans une colonne de notre banque de documents. La technologie sous-jacente de la banque est HBase, avec des niveaux personnalisés supplémentaires fournissant des fonctionnalités de contrôle d’accès et de chiffrement des données. La banque contient une ligne par fichier, et chaque colonne contient le résultat d’un extracteur spécifique. L’un des avantages essentiels de ce schéma, c’est que nous pouvons facilement modifier plusieurs colonnes d’une ligne sans craindre que les modifications apportées par un extracteur n’interfèrent avec celles des autres.
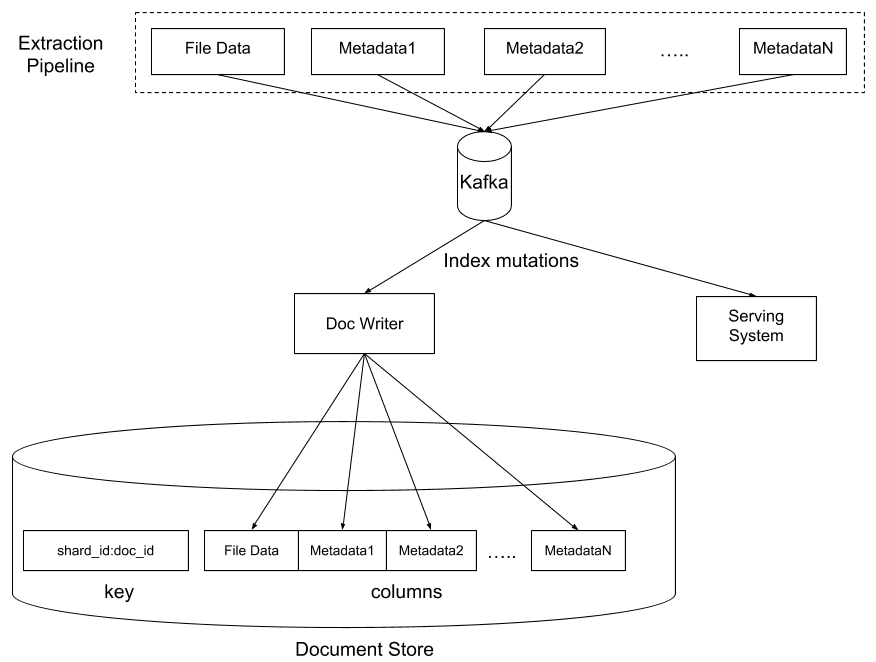
Dans la plupart des cas, nous nous appuyons sur Apache Tika pour transformer le document d’origine en représentation HTML canonique, qui est ensuite analysée afin d’en extraire une liste de « jetons » (mots) et de leurs « attributs » (mise en forme, position, etc.).
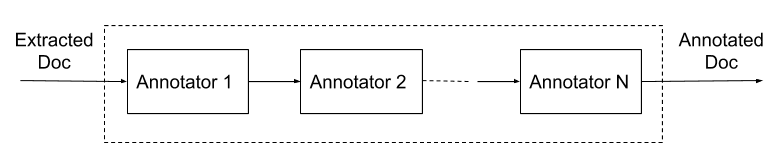
Après avoir extrait les jetons, nous pouvons enrichir les données de diverses manières à l’aide d’un processus de « compréhension des documents », particulièrement adapté aux tests d’extraction des métadonnées et signaux facultatifs. En entrée, le processus prend les données extraites du document lui-même et génère un ensemble de données additionnelles appelées « annotations ». Des modules enfichables, les « annotateurs », sont chargés de générer les annotations. Le module de stemming, ou racinisation, constitue un exemple d’annotateur simple qui génère des jetons racinisés basés sur des jetons bruts. Un autre exemple consiste à convertir les jetons en embeddings pour une recherche plus flexible.
Système hors ligne
La banque de documents contient l’intégralité du corpus de recherche, mais elle n’est pas adaptée à l’exécution des recherches puisqu’elle stocke le contenu extrait mappé par ID de document. Pour effectuer une recherche, nous avons besoin d’un index inversé, soit un mappage entre les termes de recherche et la banque de documents. Le système hors ligne est chargé de recréer périodiquement cet index de recherche à partir de la banque de documents. Il exécute l’équivalent d’une tâche MapReduce sur notre banque de documents afin de créer un index de recherche pouvant faire l’objet de requêtes très rapidement. Chaque partition se retrouve avec un ensemble de fichiers d’index stockés dans une « banque d’index » HDFS.
En séparant le processus d’extraction des documents du processus d’indexation, nous gagnons en flexibilité pour nos tests :
- Modification du format interne de l’index lui-même : nous avons aussi la possibilité de tester un nouveau format d’index améliorant les performances de récupération ou réduisant les coûts de stockage.
- Application d’un nouvel annotateur de document à l’intégralité du corpus : lorsqu’un annotateur a fait ses preuves sur un flux de nouveaux documents circulant dans le canal d’indexation instantanée, il peut être appliqué à l’ensemble du corpus de documents en deux jours, en l’ajoutant simplement au processus hors ligne. Cela permet d’accélérer les tests, au lieu d’avoir à exécuter de gros scripts de renvoi pour mettre à jour le corpus de données dans la banque de documents.
- Amélioration de l’heuristique utilisée pour filtrer les données indexées : lorsque nous traitons des centaines de milliards de contenus, il n’est pas surprenant que nous devions protéger le système contre les cas spéciaux qui pourraient nuire à la précision ou aux performances, comme des documents très volumineux ou des documents mal analysés générant des jetons brouillés. Nous utilisons plusieurs méthodes heuristiques pour filtrer de tels documents et les exclure de l’index, et nous pouvons facilement les mettre à jour avec le temps, sans devoir retraiter les documents sources à chaque fois.
- Possibilité de limiter un problème imprévu causé par un nouveau test : en cas d’erreur lors du processus d’indexation, nous pouvons simplement revenir à une version précédente de l’index. Cette protection se traduit par une tolérance aux risques et une vitesse d’itération plus élevées lors des tests.
Service
Le système de service comprend un système front-end, qui accepte et transfère les requêtes de recherche des utilisateurs ; un moteur de récupération qui génère une grande liste de documents correspondant à chaque requête ; et un système de classement nommé Octopus qui utiliser le machine learning pour classer les résultats provenant de plusieurs systèmes back-end. Nous allons nous pencher sur ces deux derniers aspects puisque le premier est composé d’un ensemble d’API plutôt simple que tous nos clients utilisent (Web, bureau et mobile).
Moteur de récupération
Le moteur de récupération est un système distribué qui récupère les documents correspondant à une requête de recherche. Ce moteur est optimisé pour des performances et un taux de rappel élevés. Il s’agit de renvoyer le plus grand ensemble de candidats possible dans le temps alloué. Ces résultats sont ensuite classés par Octopus, notre couche de fédération de recherche, afin d’atteindre un haut degré de précision, en d’autres termes, pour garantir que les résultats les plus pertinents figurent en haut de la liste. Le moteur de récupération se compose de « feuilles » et d’une « racine » :
- La racine est essentiellement chargée de déployer les requêtes entrantes auprès de l’ensemble de feuilles contenant les données, puis elle reçoit et fusionne les résultats des feuilles, avant de les renvoyer à Octopus.
- La racine inclut également un processus de « compréhension des requêtes » qui est très semblable au processus de “compréhension des documents » abordé plus haut. Il s’agit de transformer ou d’annoter une requête afin d’améliorer les résultats de récupération.
- Chaque feuille traite la recherche de documents en elle-même pour un groupe d’espaces de noms. Elle gère l’index de documents inversé et classique. La banque de données sous-jacente de l’index est RocksDB. L’index est régulièrement alimenté en téléchargeant une version du processus hors ligne, puis il est mis à jour en continu en appliquant les mutations consommées à partir des files d’attente Kafka.
Orchestrateur de recherche
Notre couche d’orchestration de recherche se nomme Octopus. Lorsqu’il reçoit la requête d’un utilisateur, la première tâche effectuée par Octopus consiste à appeler le service de contrôle d’accès de Dropbox pour déterminer l’ensemble exact d’espaces de noms auquel l’utilisateur a accès. Cet ensemble détermine le « périmètre » de la requête qui sera traitée par le moteur de récupération en aval, ce qui permet de s’assurer que seul le contenu accessible à l’utilisateur fera l’objet de la recherche.
Outre l’exploration des résultats issus du moteur de récupération de Nautilus, nous devons effectuer d’autres tâches avant de pouvoir renvoyer un ensemble de résultats final à l’utilisateur :
- Fédération : outre notre banque de documents principale et notre moteur de récupération (décrit ci-dessus), nous avons également quelques systèmes back-end auxiliaires distincts qui doivent être interrogés pour certains types de contenus. Les documents Dropbox Paper en sont un exemple : ils se trouvent actuellement sur une pile séparée. Octopus permet d’envoyer des requêtes de recherche à plusieurs moteurs de recherche back-end et de fusionner leurs résultats.
- Moteurs fantômes : la possibilité de présenter des résultats provenant de plusieurs systèmes back-end s’avère également très utile pour tester les modifications de notre système back-end de récupération principal. Durant la phase de validation, nous pouvons envoyer des requêtes de recherche au système de production et au nouveau système testé. C’est ce que l’on appelle souvent le trafic « fantôme ». Seuls les résultats du système de production sont renvoyés à l’utilisateur, mais les données des deux systèmes sont consignées pour analyse ultérieure, par exemple pour comparer les résultats de recherche ou mesurer les différences de performances.
- Classement : après avoir collecté la liste des documents candidats à partir des systèmes back-end de recherche, Octopus récupère les signaux et métadonnées supplémentaires en fonction des besoins, avant d’envoyer ces informations à un service de classement distinct, qui à son tour calcule les scores pour sélectionner la liste finale de résultats qu’il présentera à l’utilisateur.
- Vérification des listes de contrôle d’accès : le moteur de récupération limite déjà la recherche à l’ensemble d’espaces de noms défini dans le périmètre de recherche. S’ajoute à cela un niveau de protection supplémentaire au niveau d’Octopus, qui vérifie que chaque résultat renvoyé par le moteur de récupération est bien accessible par l’utilisateur ayant exécuté la requête, avant que les résultats ne soient renvoyés.
Notez que toutes ces étapes doivent se dérouler très rapidement. Notre objectif est de ne pas dépasser les 500 ms pour 95 % des recherches (autrement dit, seules 5 % des recherches devraient prendre plus de 500 ms). Dans un prochain article de blog, nous décrirons comment nous y parvenons.
Classement optimisé par le machine learning
Comme nous l’avons mentionné plus tôt, nous configurons notre moteur de récupération afin qu’il renvoie un vaste ensemble de documents correspondant à la requête, sans trop se soucier de la pertinence de chaque document pour l’utilisateur. L’étape de classement se concentre donc sur l’autre extrémité du spectre : la sélection de documents que l’utilisateur est le plus susceptible de vouloir consulter à ce moment précis. En termes techniques, le moteur de récupération est configuré pour le rappel, alors que le moteur de classement est configuré pour la précision.
Le moteur de classement est optimisé par un modèle de machine learning qui renvoie un score pour chaque document basé sur divers signaux. Certains signaux mesurent la pertinence d’un document par rapport à la requête (par exemple, BM25), alors que d’autres mesurent la pertinence du document pour l’utilisateur au moment de la recherche (par exemple, avec qui l’utilisateur a-t-il interagi dernièrement ou sur quels types de fichiers a-t-il travaillé récemment ?).
Ce modèle est entraîné à l’aide de données de « clic » anonymisées provenant de notre système front-end, qui exclut toute donnée permettant l’identification personnelle. En fonction des recherches précédentes et des résultats sur lesquels l’utilisateur a cliqué, nous pouvons en tirer des schémas de pertinence généraux. En outre, le modèle est entraîné ou modifié fréquemment : il s’adapte et il apprend des comportements globaux des utilisateurs avec le temps.
Le principal avantage d’une solution basée sur le machine learning pour le classement, c’est que nous pouvons utiliser un grand nombre de signaux et gérer les nouveaux automatiquement. On pourrait imaginer définir manuellement un degré d’importance pour chaque type de signal disponible : avec quels documents l’utilisateur a interagi récemment ou combien de fois les termes de recherche apparaissent dans le document. Ce serait réalisable avec une petite poignée de signaux, mais avec des dizaines, des centaines, voire des milliers de signaux, ce serait impossible à gérer de manière optimale. C’est là qu’intervient le machine learning : la machine peut automatiquement apprendre le bon ensemble de degrés d’importance pour le classement des documents, de sorte que les plus pertinents sont ceux qui sont présentés en priorité à l’utilisateur. Nous avons par exemple déterminé lors de nos tests que les signaux liés aux actions les plus récentes contribuaient significativement à la pertinence des résultats.
Conclusion
Après une période de test pendant laquelle Nautilus était exécuté en mode fantôme, il s’agit maintenant du moteur de recherche principal de Dropbox. Nous avons déjà pu observer des améliorations considérables au niveau du temps requis pour l’indexation des nouveaux contenus et des contenus mis à jour.
Maintenant que nous avons posé des bases solides, notre équipe travaille sur de nouvelles fonctionnalités et sur l’amélioration de la qualité des recherches de la plateforme Nautilus. Nous explorons actuellement de nouvelles possibilités, comme l’enrichissement de l’algorithme de récupération des listes de valeur, avec une récupération basée sur la distance dans un espace d’embedding, la recherche de fichiers image, vidéo et audio à l’aide de l’ajout automatisé de tags, l’amélioration de la personnalisation en utilisant des signaux d’activité utilisateur supplémentaires, et bien plus encore.
Nautilus est un exemple parfait d’utilisation des technologies de récupération de données et de machine learning à grande échelle chez Dropbox. Si ce type de problématique vous intéresse, nous aimerions beaucoup vous compter parmi nous.




