Validation des performances et de la fiabilité du nouveau moteur de recherche Dropbox

Dans notre article précédent, nous avons discuté de l’architecture et des capacités de machine learning de notre nouveau moteur de recherche, Nautilus. Dans cet article, nous allons présenter les mesures que nous avons prises pour garantir une fiabilité et des performances optimales.
Performances
Format de l’index
Chacune des centaines de feuilles de recherche exécute notre moteur de récupération, dont certaines des responsabilités incluent la mise à jour de l’index lors de la création, la modification et la suppression de fichiers (écritures), ainsi que le traitement des requêtes de recherche (lectures). Le trafic de Dropbox est intéressant, car il est dominé par des écritures : les fichiers sont modifiés bien plus fréquemment qu’ils ne sont recherchés. Nous observons généralement un volume d’écritures dix fois plus élevé que le volume de lectures. De ce fait, nous avons scrupuleusement pris en compte ces charges de travail lors de l’optimisation des structures de données utilisées par le moteur de récupération.
Une liste de valeurs (posting list) est une structure de données qui mappe un jeton (autrement dit un terme de recherche potentiel) à la liste de documents contenant ce jeton. La responsabilité de base d’un moteur de récupération est de gérer un ensemble de listes de valeurs constituant l’index inversé. Les listes de valeurs sont interrogées pendant les requêtes de recherche, et elles sont actualisées en cas de mise à jour de l’index. L’un des formats de liste de valeurs les plus courants consiste en un jeton et une liste d’ID de documents, avec des métadonnées pouvant être utilisées pendant l’étape d’attribution du score (fréquence du terme, par exemple).

Ce format est idéal pour les charges de travail essentiellement en lecture seule : pour chaque requête de recherche, il faut uniquement trouver l’ensemble approprié de listes de valeurs (qui peut être O(1) avec une table de hachage), puis ajouter chacun des ID de documents associés à l’ensemble de résultats.
Mais pour pouvoir gérer les taux d’écriture élevés observés dans le comportement de nos utilisateurs, nous avons pris la décision d’utiliser un format de liste de valeurs « éclaté » dans l’index inversé. Notre index inversé s’appuie sur un magasin de clés/valeurs (RocksDB) et chaque tuple `(namespace ID, token, document ID)` est stocké sur une ligne distincte. Pour être plus précis, le format de la clé de ligne est ` »« <namespace ID>|<token>|<doc ID>« « `. En fonction de la requête de recherche exécutée sur les documents d’un espace de noms spécifique, nous pouvons effectuer une recherche de préfixes pour `<« namespace ID><« token>|` dans l’index pour obtenir une liste de tous les documents correspondants. Avoir le concept d’espace de noms intégré au format de la clé présente plusieurs avantages. Tout d’abord, et c’est le plus important, il n’y a aucun risque qu’une requête renvoie des documents se trouvant en dehors de l’espace de noms auquel l’utilisateur a accès. Ensuite, la recherche porte uniquement sur les documents inclus dans les espaces de noms, et non sur les ensembles de documents beaucoup plus grands indexés dans la partition. Avec ce schéma, la valeur de chaque ligne inclut les métadonnées associées au jeton.
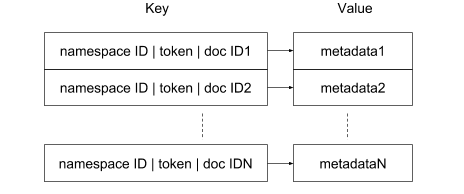
En matière de stockage et de récupération, cette approche est moins efficace que le format conventionnel, où tous les ID de document sont regroupés et peuvent être stockés dans une représentation compacte en utilisant des techniques comme le codage différentiel. Par contre, la représentation « éclatée » a le mérite de pouvoir gérer les mutations d’index de manière particulièrement efficace. Par exemple, un document est ajouté à l’index inversé en insérant une ligne pour chaque jeton qu’il contient : il s’agit d’une opération simple qui s’exécute très efficacement sur la plupart des magasins de clés/valeurs, y compris RocksDB. Cette pénalité de stockage supplémentaire est contrebalancée par le fait que RocksDB compresse le préfixe des clés. Nous avons globalement observé que la taille des index utilisant une représentation éclatée était seulement 15 % supérieure à celle des index utilisant une représentation classique avec listes de valeurs.
Service
Des performances rapides sont essentielles pour obtenir une expérience utilisateur fluide et interactive. La première mesure que nous utilisons pour évaluer les performances de service est la latence des requêtes au 95e et au 99e centile, c’est-à-dire que les 5 % et 1 % des requêtes les plus lentes ne doivent pas prendre plus de 500 ms et 1 s, respectivement (actuellement). La requête médiane sera bien évidemment beaucoup plus rapide. Pendant le développement de Nautilus, nous avons mesuré et analysé ses performances en continu. Chaque composant du système est mesuré afin de pouvoir déterminer son rôle dans la latence globale. Nous avons appris quelques leçons en chemin :
– Ne pas optimiser prématurément : nous avons attendu de comprendre l’impact de chaque composant du système sur la latence globale pour améliorer les performances du moteur de récupération. On aurait pu s’attendre à ce que le plus gros du délai soit dû à la phase de récupération. Toutefois, après une analyse initiale des données, nous avons déterminé qu’une grande partie de la latence provenait en fait de la récupération des métadonnées à partir des systèmes externes, qui sont basés sur des bases de données relationnelles, pour vérifier des listes de contrôle d’accès et enrichir les résultats de recherche avant de les renvoyer. Ces métadonnées incluent des informations comme le chemin de dossier, son créateur, la date et l’heure de la dernière modification, etc.
- Faire attention à la « requête de la mort » : certaines requêtes nuisibles peuvent considérablement affecter la latence globale. On les appelle parfois les « requêtes de la mort ». Elles proviennent généralement d’erreurs logicielles qui touchent la programmation de l’API de recherche, et non d’utilisateurs humains. Nous avons conçu des disjoncteurs qui filtrent ces requêtes afin de protéger le système dans son ensemble. En outre, nous avons mis en place la possibilité de respecter un « budget temporel », où le moteur de récupération arrête d’aller chercher les candidats d’une requête une fois le temps alloué dépassé. D’après nos analyses, cette restriction a une incidence positive sur les performances et sur la charge globale du système, mais parfois aux dépens de l’exhaustivité des résultats. Cela se produit généralement pour les requêtes très vastes, correspondant à de nombreux candidats : par exemple en cas de recherche de préfixe sur un seul jeton (comme cela arrive pendant la saisie semi-automatique des requêtes de recherche).
- Utiliser les réplicas pour diminuer les pics de latence : nos feuilles sont dédoublées pour garantir la redondance au cas où la machine rencontrerait des problèmes. Cependant, ces réplicas représentent également un avantage en matière de performances : ils peuvent être utilisés pour améliorer les pics de latence (la latence des requêtes les plus lentes). Nous utilisons la technique courante qui consiste à envoyer une requête à tous les réplicas et à renvoyer la réponse du réplica le plus rapide.
- Investir dans la création d’outils de benchmarking : une fois qu’un composant spécifique est identifié comme étant un goulot d’étranglement en matière de performances, la création d’un outil de benchmarking pour tester la charge et mesurer les performances de ce composant spécifique est le meilleur moyen d’accélérer les itérations pour améliorer les performances plutôt que de tester l’intégralité du système. Dans notre cas, nous avons créé un outil de benchmarking pour le moteur de récupération principal s’exécutant sur les feuilles. Nous l’avons utilisé pour mesurer les performances d’indexation et de récupération du moteur au niveau des partitions en fonction de données synthétiques. Les données des partitions ont été générées pour présenter des caractéristiques semblables à celles des données de production en termes de nombre total d’espaces de noms, de documents et de jetons, en termes de distribution du nombre de documents par espace de noms, et en termes de nombre de jetons par document.
Fiabilité
Des millions d’utilisateurs comptent sur la fonctionnalité de recherche Dropbox pour faire leur travail. Nous avons donc porté une attention toute particulière à la conception du système pour garantir la disponibilité que nos utilisateurs attendent.
Dans un grand système distribué, des pannes réseau ou matérielles et des incidents logiciels se produisent régulièrement, et sont inévitables. Nous avons gardé cela à l’esprit lorsque nous avons développé Nautilus. Nous nous sommes particulièrement concentrés sur la tolérance aux pannes et la récupération automatique des composants se trouvant sur le chemin de service.
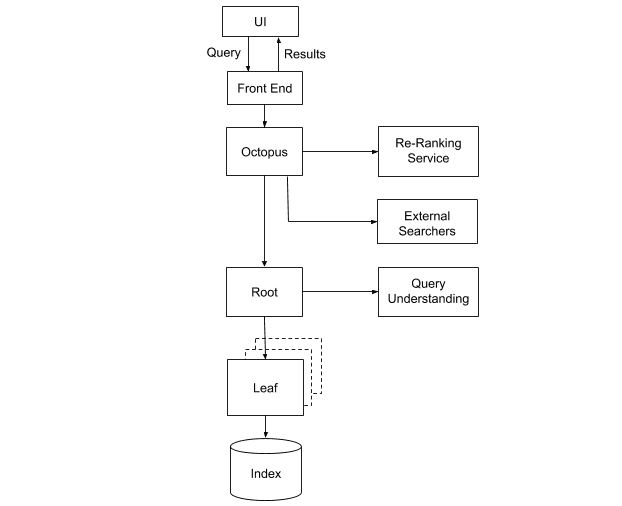
Certains des composants ont été conçus pour être sans état, c’est-à-dire qu’ils ne s’appuient sur aucun service ni donnée externe pour fonctionner. Octopus, notre système de fusionnement et de classement des résultats, et la racine de notre moteur de récupération, qui déploie les requêtes de recherche vers toutes les feuilles, en font partie. Ces services peuvent donc facilement être déployés dans plusieurs instances, chacune d’entre elles pouvant être automatiquement reprovisionnée en cas de défaillance. Le problème est plus épineux lorsque cela touche les instances de feuilles, puisqu’elles gèrent les données d’index.
Attribution des partitions
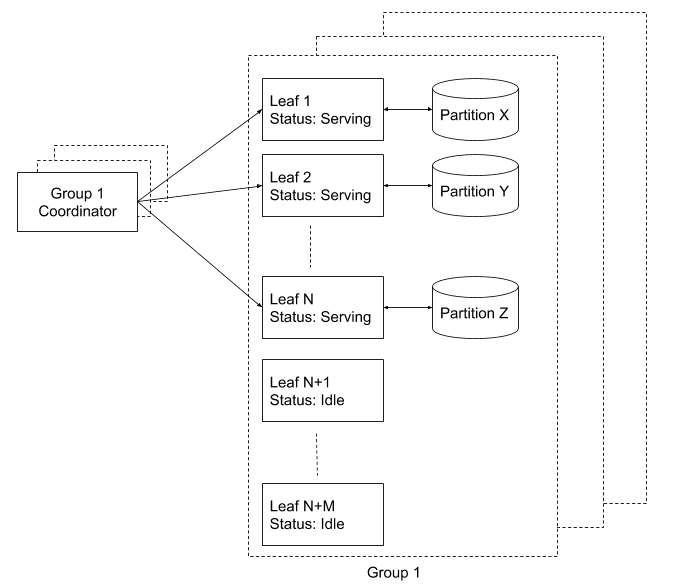
Dans Nautilus, chaque instance de feuille est chargée de la gestion d’un sous-ensemble d’index de recherche, appelé « partition ». Nous gérons un registre de toutes les feuilles et leur attribuons des partitions via un coordinateur séparé (optimisé par Zookeeper). Le coordinateur assure la couverture continue de la totalité des partitions. Chaque nouvelle instance de feuille reste inactive jusqu’à ce que le coordinateur lui demande de servir une partition, auquel cas elle charge l’index et commence à accepter des requêtes de recherche.
Que se passe-t-il si une feuille est sur le point d’être mise en service, mais qu’une requête de recherche est en cours d’exécution sur les données de sa partition ? Nous réglons ce problème en conservant des réplicas de chaque feuille, qui une fois réunis se nomment « groupes de réplicas de feuilles ». Un groupe de réplicas est un cluster indépendant d’instances de feuilles permettant de couvrir intégralement l’index. Par exemple, pour garantir une réplication X2 du système, nous exécutons deux groupes de réplicas, avec un coordinateur par groupe. Outre la simplification du raisonnement sur la réplication, cette configuration présente également des avantages opérationnels en matière de maintenance :
- Du nouveau code peut être déployé en production sans impact sur la disponibilité, simplement en le déployant dans les groupes, l’un après l’autre.
- Il est possible d’ajouter ou de supprimer tout un groupe dans son ensemble, ce qui peut être assez pratique lors des mises à niveau du matériel ou du système d’exploitation. Par exemple, un groupe s’exécutant sur du nouveau matériel peut être ajouté, et une fois entièrement opérationnel, nous pouvons désactiver le groupe s’exécutant sur l’ancien matériel.
Dans ces deux cas, Nautilus est à même de répondre à toutes les requêtes tout au long du processus.
Récupération
Chaque groupe de feuilles est surprovisionné avec environ 15 % de capacité matérielle supplémentaire pour obtenir un pool d’instances inactives en stand-by. Lorsque le coordinateur détecte une baisse dans la couverture des partitions (par exemple, une feuille active s’arrête soudainement de servir les requêtes), il choisit une feuille inactive et lui demande de servir la partition perdue. Cette feuille exécute ensuite les étapes suivantes :
- Elle télécharge les données d’index associées à la partition depuis le référentiel d’index. La feuille dispose alors d’un index périmé puisqu’il a été généré il y a un certain temps par le système hors ligne.
- Elle rejoue les anciennes mutations de la file d’attente Kafka en commençant à l’offset correspondant au moment de la création de la partition de l’index.
- Après l’application de ces anciennes mutations à l’index téléchargé, l’index de la feuille est à jour. À ce stade, la feuille passe en mode de service et commence à traiter les requêtes.




